Određivanje empirijske funkcije distribucije
Neka je $X$ slučajna varijabla. $F(x)$ je funkcija distribucije date slučajne varijable. Provešćemo $n$ eksperimente na datoj slučajnoj promenljivoj pod istim uslovima, nezavisno jedan od drugog. U ovom slučaju dobijamo niz vrijednosti $x_1,\ x_2\ $, ... ,$\ x_n$, koji se naziva uzorak.
Definicija 1
Svaka vrijednost $x_i$ ($i=1,2\ $, ... ,$ \ n$) naziva se varijanta.
Jedna procjena teorijske funkcije distribucije je empirijska funkcija distribucije.
Definicija 3
Empirijska funkcija distribucije $F_n(x)$ je funkcija koja za svaku vrijednost $x$ određuje relativnu frekvenciju događaja $X \
gdje je $n_x$ broj opcija manji od $x$, $n$ je veličina uzorka.
Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerovatnoću događaja $X
Svojstva empirijske funkcije distribucije
Razmotrimo sada nekoliko osnovnih svojstava funkcije distribucije.
Opseg funkcije $F_n\left(x\right)$ je segment $$.
$F_n\left(x\right)$ je neopadajuća funkcija.
$F_n\left(x\right)$ je lijeva kontinuirana funkcija.
$F_n\left(x\right)$ je konstantna funkcija po komadima i raste samo u tačkama vrijednosti slučajne varijable $X$
Neka je $X_1$ najmanja, a $X_n$ najveća varijanta. Tada je $F_n\left(x\right)=0$ za $(x\le X)_1$ i $F_n\left(x\right)=1$ za $x\ge X_n$.
Hajde da uvedemo teoremu koja povezuje teorijske i empirijske funkcije.
Teorema 1
Neka je $F_n\left(x\right)$ empirijska funkcija raspodjele, a $F\left(x\right)$ teorijska funkcija raspodjele općeg uzorka. Tada vrijedi jednakost:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Primjeri problema za pronalaženje empirijske funkcije raspodjele
Primjer 1
Neka distribucija uzorkovanja ima sljedeće podatke zabilježene pomoću tabele:
Slika 1.
Pronađite veličinu uzorka, kreirajte empirijsku funkciju distribucije i nacrtajte je.
Veličina uzorka: $n=5+10+15+20=50$.
Prema svojstvu 5, imamo da je za $x\le 1$ $F_n\left(x\right)=0$, a za $x>4$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Tako dobijamo:
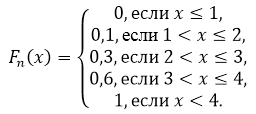
Slika 2.

Slika 3.
Primjer 2
Iz gradova centralnog dela Rusije nasumično je odabrano 20 gradova za koje su dobijeni sledeći podaci o cenama prevoza: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14.
Kreirajte empirijsku funkciju distribucije za ovaj uzorak i nacrtajte je.
Zapišimo vrijednosti uzorka uzlaznim redoslijedom i izračunajmo učestalost svake vrijednosti. Dobijamo sledeću tabelu:
Slika 4.
Veličina uzorka: $n=20$.
Prema svojstvu 5, imamo da je za $x\le 12$ $F_n\left(x\right)=0$, a za $x>15$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Tako dobijamo:

Slika 5.
Nacrtajmo empirijsku distribuciju:
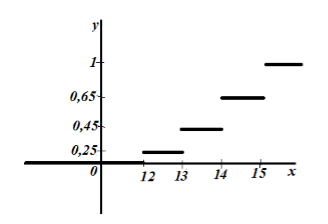
Slika 6.
Originalnost: $92,12\%$.
Predavanje 13. Koncept statističkih procjena slučajnih varijabli
Neka je poznata statistička frekvencijska distribucija kvantitativne karakteristike X. Označimo sa brojem opažanja u kojima je uočena vrijednost karakteristike manja od x i sa n ukupan broj opservacija. Očigledno, relativna učestalost događaja X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Empirijska funkcija distribucije(funkcija distribucije uzorkovanja) je funkcija koja za svaku vrijednost x određuje relativnu frekvenciju događaja X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
Za razliku od empirijske funkcije distribucije uzorka, naziva se funkcija raspodjele populacije teorijska funkcija distribucije. Razlika između ovih funkcija je u tome što teorijska funkcija određuje vjerovatnoća događaji X< x, тогда как эмпирическая – relativna frekvencija isti događaj.
Kako n raste, relativna frekvencija događaja X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Svojstva empirijske funkcije distribucije:
1) Vrijednosti empirijske funkcije pripadaju segmentu
2) - neopadajuća funkcija
3) Ako je najmanja opcija, onda = 0 za , ako je najveća opcija, onda = 1 za .
Empirijska funkcija distribucije uzorka služi za procjenu teorijske funkcije distribucije populacije.
Primjer. Konstruirajmo empirijsku funkciju na osnovu distribucije uzorka:
| Opcije | |||
| Frekvencije |
Nađimo veličinu uzorka: 12+18+30=60. Najmanja opcija je 2, dakle =0 za x £ 2. Vrijednost x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Dakle, željena empirijska funkcija ima oblik:
Najvažnija svojstva statističke procjene
Neka je potrebno proučiti neke kvantitativne karakteristike opšte populacije. Pretpostavimo da je iz teorijskih razmatranja to bilo moguće utvrditi koji tačno raspodjela ima predznak i potrebno je procijeniti parametre po kojima se ona određuje. Na primjer, ako je karakteristika koja se proučava normalno raspoređena u populaciji, tada je potrebno procijeniti matematičko očekivanje i standardnu devijaciju; ako karakteristika ima Poissonovu distribuciju, tada je potrebno procijeniti parametar l.
Obično su dostupni samo uzorci podataka, na primjer, vrijednosti kvantitativne karakteristike dobivene kao rezultat n neovisnih promatranja. Uzimajući u obzir nezavisne slučajne varijable možemo to reći pronaći statističku procjenu nepoznatog parametra teorijske distribucije znači pronaći funkciju promatranih slučajnih varijabli koja daje približnu vrijednost procijenjenog parametra. Na primjer, da bi se procijenilo matematičko očekivanje normalne distribucije, ulogu funkcije igra aritmetička sredina
Da bi statističke procjene dale ispravne aproksimacije procijenjenih parametara, one moraju zadovoljiti određene zahtjeve, među kojima su najvažniji zahtjevi undisplaced I solventnost procjene.
Neka je statistička procjena nepoznatog parametra teorijske distribucije. Neka se procjena nađe iz uzorka veličine n. Ponovimo eksperiment, tj. hajde da izdvojimo drugi uzorak iste veličine iz opšte populacije i na osnovu njegovih podataka dobijemo drugačiju procenu. Ponavljajući eksperiment mnogo puta, dobijamo različite brojeve. Rezultat se može posmatrati kao slučajna varijabla, a brojevi kao njene moguće vrijednosti.
Ako procjena daje približnu vrijednost u izobilju, tj. svaki broj je veći od prave vrijednosti, i kao posljedica toga, matematičko očekivanje (prosječna vrijednost) slučajne varijable je veće od:. Isto tako, ako daje procjenu sa nedostatkom, To .
Dakle, upotreba statističke procjene, čije matematičko očekivanje nije jednako procijenjenom parametru, dovela bi do sistematskih (istog predznaka) grešaka. Ako, naprotiv, onda to garantuje od sistematskih grešaka.
Nepristrasan naziva se statistička procjena, čije je matematičko očekivanje jednako procijenjenom parametru za bilo koju veličinu uzorka.
Displaced naziva se procjena koja ne zadovoljava ovaj uslov.
Nepristranost procjene još ne garantuje dobru aproksimaciju procijenjenog parametra, budući da se moguće vrijednosti mogu veoma raštrkano oko svoje prosječne vrijednosti, tj. varijansa može biti značajna. U ovom slučaju, procjena pronađena iz podataka jednog uzorka, na primjer, može se pokazati značajno udaljenom od prosječne vrijednosti, a samim tim i od parametra koji se procjenjuje.
Efektivno je statistička procjena koju, za datu veličinu uzorka n, ima najmanju moguću varijaciju .
Kada se razmatraju veliki uzorci, potrebne su statističke procjene solventnost .
Bogati naziva se statistička procjena, koja, kako n®¥ teži po vjerovatnoći procijenjenom parametru. Na primjer, ako varijansa nepristrasne procjene teži nuli kao n®¥, onda se takva procjena ispostavi da je konzistentna.
Određivanje empirijske funkcije distribucije
Neka je $X$ slučajna varijabla. $F(x)$ je funkcija distribucije date slučajne varijable. Provešćemo $n$ eksperimente na datoj slučajnoj promenljivoj pod istim uslovima, nezavisno jedan od drugog. U ovom slučaju dobijamo niz vrijednosti $x_1,\ x_2\ $, ... ,$\ x_n$, koji se naziva uzorak.
Definicija 1
Svaka vrijednost $x_i$ ($i=1,2\ $, ... ,$ \ n$) naziva se varijanta.
Jedna procjena teorijske funkcije distribucije je empirijska funkcija distribucije.
Definicija 3
Empirijska funkcija distribucije $F_n(x)$ je funkcija koja za svaku vrijednost $x$ određuje relativnu frekvenciju događaja $X \
gdje je $n_x$ broj opcija manji od $x$, $n$ je veličina uzorka.
Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerovatnoću događaja $X
Svojstva empirijske funkcije distribucije
Razmotrimo sada nekoliko osnovnih svojstava funkcije distribucije.
Raspon funkcije $F_n\left(x\right)$ -- linijski segment $$.
$F_n\left(x\right)$ je neopadajuća funkcija.
$F_n\left(x\right)$ je lijeva kontinuirana funkcija.
$F_n\left(x\right)$ je konstantna funkcija po komadima i raste samo u tačkama vrijednosti slučajne varijable $X$
Neka je $X_1$ najmanja, a $X_n$ najveća varijanta. Tada je $F_n\left(x\right)=0$ za $(x\le X)_1$ i $F_n\left(x\right)=1$ za $x\ge X_n$.
Hajde da uvedemo teoremu koja povezuje teorijske i empirijske funkcije.
Teorema 1
Neka je $F_n\left(x\right)$ empirijska funkcija raspodjele, a $F\left(x\right)$ teorijska funkcija raspodjele općeg uzorka. Tada vrijedi jednakost:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Primjeri problema za pronalaženje empirijske funkcije raspodjele
Primjer 1
Neka distribucija uzorkovanja ima sljedeće podatke zabilježene pomoću tabele:
Slika 1.
Pronađite veličinu uzorka, kreirajte empirijsku funkciju distribucije i nacrtajte je.
Veličina uzorka: $n=5+10+15+20=50$.
Prema svojstvu 5, imamo da je za $x\le 1$ $F_n\left(x\right)=0$, a za $x>4$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Tako dobijamo:
Slika 2.
Slika 3.
Primjer 2
Iz gradova centralnog dela Rusije nasumično je odabrano 20 gradova za koje su dobijeni sledeći podaci o cenama prevoza: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14.
Kreirajte empirijsku funkciju distribucije za ovaj uzorak i nacrtajte je.
Zapišimo vrijednosti uzorka uzlaznim redoslijedom i izračunajmo učestalost svake vrijednosti. Dobijamo sledeću tabelu:
Slika 4.
Veličina uzorka: $n=20$.
Prema svojstvu 5, imamo da je za $x\le 12$ $F_n\left(x\right)=0$, a za $x>15$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Tako dobijamo:
Slika 5.
Nacrtajmo empirijsku distribuciju:
Slika 6.
Originalnost: $92,12\%$.
Prosek uzorka.
Neka se izdvoji uzorak veličine n da bi se proučavala opšta populacija u pogledu kvantitativne karakteristike X.
Srednja vrijednost uzorka je aritmetička sredina karakteristike u populaciji uzorka.
![]()
Varijanca uzorka.
Da bi se uočila disperzija kvantitativne karakteristike vrijednosti uzorka oko njene prosječne vrijednosti, uvodi se zbirna karakteristika - varijansa uzorka.
Varijanca uzorka je aritmetička sredina kvadrata odstupanja posmatranih vrijednosti karakteristike od njihove srednje vrijednosti.
Ako su sve vrijednosti karakteristike uzorka različite, onda

Ispravljena varijansa.
Varijanca uzorka je pristrasna procjena varijanse populacije, tj. matematičko očekivanje varijanse uzorka nije jednako procijenjenoj opštoj varijansi, ali je jednako
![]()
Da biste ispravili varijansu uzorka, jednostavno je pomnožite s razlomkom
Koeficijent korelacije uzorka nalazi se po formuli

gdje su standardne devijacije vrijednosti uzorka i .
Koeficijent korelacije uzorka pokazuje bliskost linearnog odnosa između i : što je bliže jedinici, to je jača linearna veza između i .
23. Frekvencijski poligon je izlomljena linija čiji segmenti spajaju tačke. Da bi se konstruisao poligon frekvencija, varijante su iscrtane na osi apscisa, a odgovarajuće frekvencije su nacrtane na osi ordinata, a tačke su povezane linijskim segmentima.
Poligon relativne frekvencije se konstruiše na sličan način, osim što su relativne frekvencije iscrtane na osi ordinata.
Histogram frekvencije je stepenasta figura koja se sastoji od pravokutnika, čije su osnove parcijalni intervali dužine h, a visine su jednake omjeru. Za konstruiranje histograma frekvencije, parcijalni intervali se postavljaju na os apscise, a segmenti paralelni s osom apscise na udaljenosti (visini) se crtaju iznad njih. Površina i-tog pravougaonika jednaka je zbiru frekvencija i-o intervala, stoga je površina histograma frekvencije jednaka zbiru svih frekvencija, tj. veličina uzorka.


Empirijska funkcija distribucije
Gdje n x- broj vrijednosti uzorka manji od x; n- veličina uzorka.
22 Definirajmo osnovne koncepte matematičke statistike
.Osnovni pojmovi matematičke statistike. Populacija i uzorak. Varijabilne serije, statističke serije. Grupirani uzorak. Grupirane statističke serije. Frekvencijski poligon. Funkcija distribucije uzorka i histogram.
Populacija– cijeli skup dostupnih objekata.
Uzorak– skup objekata nasumično odabranih iz opće populacije.
Poziva se niz opcija napisanih u rastućem redoslijedu varijacijski u blizini, i listu opcija i njihovih odgovarajućih frekvencija ili relativnih frekvencija - statističke serije: nasumično odabrano iz opće populacije.
Poligon frekvencije se naziva izlomljena linija, čiji segmenti spajaju tačke.
Histogram frekvencije je stepenasta figura koja se sastoji od pravokutnika, čije su osnovice parcijalni intervali dužine h, a visine su jednake omjeru .
Uzorak (empirijska) funkcija distribucije pozovite funkciju f*(x), definiranje za svaku vrijednost X relativna učestalost događaja X< x.
Ako se proučava neka kontinuirana osobina, tada se serija varijacija može sastojati od vrlo velika količina brojevi. U ovom slučaju je praktičniji za korištenje grupisani uzorak. Da bi se dobio, interval koji sadrži sve promatrane vrijednosti atributa dijeli se na nekoliko jednakih parcijalnih intervala dužine h, a zatim pronađite za svaki parcijalni interval n i– zbir frekvencija varijante uključene u i th interval.
20. Zakon velikih brojeva ne treba shvatiti kao bilo koji opšti zakon povezan sa velikim brojevima. Zakon velikih brojeva je generalizirani naziv za nekoliko teorema, iz kojih slijedi da s neograničenim povećanjem broja pokušaja prosječne vrijednosti teže određenim konstantama.
To uključuje teoreme Čebiševa i Bernulija. Čebiševljeva teorema je najopštiji zakon velikih brojeva.
Dokaz teorema, ujedinjen pojmom "zakon velikih brojeva", zasniva se na Čebiševovoj nejednakosti, koja utvrđuje vjerovatnoću odstupanja od svog matematičkog očekivanja:
![]()
19Pearsonova distribucija (hi - kvadrat) - raspodjela slučajne varijable
gdje su slučajne varijable X 1, X 2,…, X n nezavisni i imaju istu distribuciju N(0,1). U ovom slučaju, broj pojmova, tj. n, se naziva „broj stepena slobode“ hi-kvadrat raspodele.
Hi-kvadrat distribucija se koristi kada se procjenjuje varijansa (koristeći interval povjerenja), kada se testiraju hipoteze slaganja, homogenosti, nezavisnosti,
Distribucija t Studentov t je distribucija slučajne varijable
gdje su slučajne varijable U I X nezavisni, U ima standardnu normalnu distribuciju N(0.1), i X– hi raspodjela – kvadrat c n stepena slobode. Gde n se naziva „broj stepena slobode“ Studentove distribucije.
Koristi se pri procjeni matematičkog očekivanja, vrijednosti prognoze i drugih karakteristika korištenjem intervala povjerenja, testiranja hipoteza o vrijednostima matematičkih očekivanja, koeficijenata regresije,
Fisherova distribucija je distribucija slučajne varijable
Fisherova distribucija se koristi kada se testiraju hipoteze o adekvatnosti modela u regresionoj analizi, jednakosti varijansi i drugim problemima primijenjene statistike.
18Linearna regresija je statistički alat koji se koristi za predviđanje budućih cijena na osnovu prošlih podataka i obično se koristi za određivanje kada su cijene pregrijane. Metoda najmanjih kvadrata se koristi za konstruisanje „najbolje“ prave linije kroz niz tačaka vrednosti cene. Cenovne tačke koje se koriste kao ulaz mogu biti bilo koje od sledećeg: otvorene, zatvorene, visoke, niske,
17. Dvodimenzionalna slučajna varijabla je uređeni skup od dvije slučajne varijable ili .
Primjer: Bacaju se dvije kockice. – broj bodova bačenih na prvoj i drugoj kocki, respektivno
Univerzalni način da se specificira zakon distribucije dvodimenzionalne slučajne varijable je funkcija distribucije.
15.m.o Diskretne slučajne varijable
Svojstva:
1) M(C) = C, C- konstantan;
2) M(CX) = CM.(X);
3) M(X 1 + X 2) = M(X 1) + M(X 2), Gdje X 1, X 2- nezavisne slučajne varijable;
4) M(X 1 X 2) = M(X 1)M(X 2).
Matematičko očekivanje zbira slučajnih varijabli jednako je zbiru njihovih matematičkih očekivanja, tj.
Matematičko očekivanje razlike između slučajnih varijabli jednako je razlici njihovih matematičkih očekivanja, tj.
Matematičko očekivanje proizvoda slučajnih varijabli jednako je proizvodu njihovih matematičkih očekivanja, tj.
Ako se sve vrijednosti slučajne varijable povećaju (smanje) za isti broj C, tada će se njeno matematičko očekivanje povećati (smanjiti) za isti broj
14. Eksponencijalno(eksponencijalna)zakon o distribuciji X ima eksponencijalni zakon raspodjele s parametrom λ >0 ako njegova gustina vjerovatnoće ima oblik:
![]()
Očekivana vrijednost: .
Disperzija: .
Zakon eksponencijalne distribucije igra veliku ulogu u teoriji čekanja i teoriji pouzdanosti.
13. Zakon normalne distribucije karakterizira učestalost otkaza a (t) ili gustina vjerovatnoće otkaza f (t) u obliku:
 , (5.36)
, (5.36)
gdje je σ standardna devijacija SV x;
m x– matematičko očekivanje SV x. Ovaj parametar se često naziva centar disperzije ili najvjerovatnija vrijednost SV X.
x– slučajna varijabla, koja se može uzeti kao vrijeme, vrijednost struje, vrijednost električnog napona i drugi argumenti.
Normalni zakon je zakon sa dva parametra, za pisanje kojeg trebate znati m x i σ.
Normalna distribucija (Gaussova distribucija) se koristi za procjenu pouzdanosti proizvoda na koje utječe niz nasumičnih faktora, od kojih svaki ima blagi utjecaj na rezultirajući učinak
12. Zakon o jedinstvenoj distribuciji. Kontinuirana slučajna varijabla X ima uniforman zakon raspodjele na segmentu [ a, b], ako je njegova gustina vjerovatnoće konstantna na ovom segmentu i jednaka nuli izvan njega, tj.

Oznaka: .
Očekivana vrijednost: .
Disperzija: .
Slučajna vrijednost X, raspoređena prema uniformnom zakonu na segmentu se zove slučajni broj od 0 do 1. Služi kao polazni materijal za dobijanje slučajnih varijabli sa bilo kojim zakonom raspodjele. Ujednačeni zakon distribucije koristi se u analizi grešaka zaokruživanja pri izvođenju numeričkih proračuna, u nizu problema čekanja, u statističkom modeliranju opservacija koje su predmet date raspodjele.
11. Definicija. Gustina distribucije vjerovatnoća kontinuirane slučajne varijable X naziva se funkcija f(x)– prvi izvod funkcije distribucije F(x).
Gustina distribucije se također naziva diferencijalna funkcija. Za opisivanje diskretne slučajne varijable, gustina distribucije je neprihvatljiva.
Značenje gustine distribucije je da pokazuje koliko se često slučajna varijabla X pojavljuje u određenom susjedstvu tačke X pri ponavljanju eksperimenata.
Nakon uvođenja funkcija raspodjele i gustine distribucije, može se dati sljedeća definicija kontinuirane slučajne varijable.
10. Gustoća vjerovatnoće, gustina distribucije vjerovatnoće slučajne varijable x, je funkcija p(x) takva da 
i za bilo koje a< b вероятность события a < x < b равна
.
Ako je p(x) kontinuiran, onda je za dovoljno mali ∆x vjerovatnoća nejednakosti x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
i ako je F(x) diferencijabilna, onda ![]()